


Conducting swift experiments to assess model performance
For people working in technology, generative AI is part of their daily routine. Nowadays, there are many tools that use generative AI, in addition to numerous LLM providers who constantly release updates regarding performance, accuracy, and variety of uses. However, it is undeniable that the data used to train these models contain biases, one of the most notable being language.
English is often referred to as the language of dissemination, and in technology, the entire world has adapted to using software that is in English, at least those with recent updates and features. The creators of these models have, of course, considered training models in other languages, at least those with more speakers.
At CodeGPT, we interact daily with developers and businesses (from all sectors) around the world. Therefore, we consider it very important to have products that adapt to their needs, country regulations, culture, and language.
Recently, an interesting case came up, which inspired us to carry out this experiment, the requirements of our client were:
- The model must run on a local server, due to data regulation in the cloud.
- The model must respond fluently in English and Classical Arabic.
- Response times must be optimal to simulate a fluid conversation.
We are going to use some metrics to validate the agents' responses. We will use the following as a reference:
- Best practices for building bots with Composer
- Custom question answering best practices
- Ragas metrics just for the answers
After reading the references, we decide to take the following metrics:
- Accuracy: if the agent's response matches the real answer from 0–1.
- Grammar: if the response is grammatically correct, check no errors(1), some errors(0.75), Gender and number errors(0.5).
- Relevance: if the response corresponds to the question, if is relevant(1) or not(0).
- Completeness: if the response contains all the necessary information to answer the question, if is complete(1) or not(0).
- Additionally, we measure the response generation time, in seconds.
Methodology
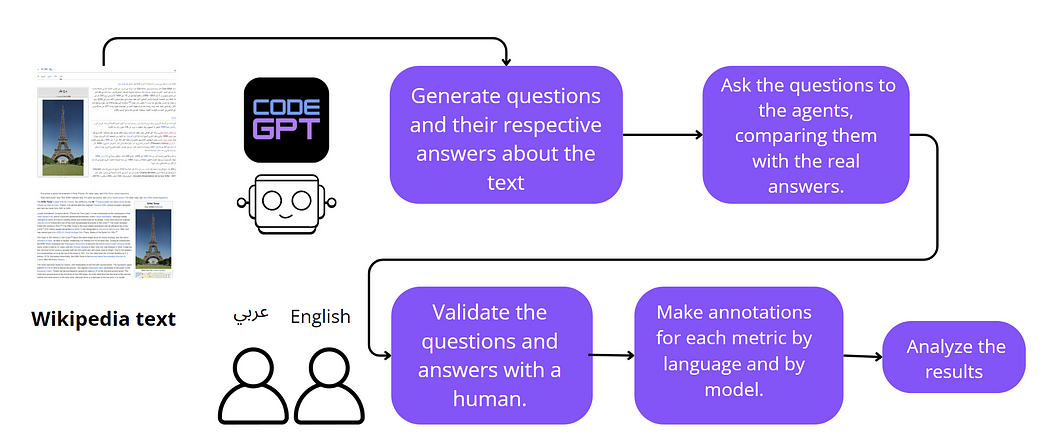
To conduct the experiment, we selected English and Arabic text from Wikipedia about the Eiffel Tower. We then added this text as a knowledge base to an agent, which generated 20 questions along with their respective answers. The agent's prompt was as follows:
You are an agent that generates questions and answers based on a context. The user will paste the text and you should formulate 20 questions and answers from this text. The number of questions will always be 20, and they should be displayed in the following way, for example:
Questions: 1. How often is the Eiffel Tower painted from the first floor to the top? Answers: 1. Every 5-7 years.
With the assistance of a native Arabic speaker and an English speaker, we were able to validate the agent's responses by comparing them with the Wikipedia text. Even knowing that models in general contain text from Wikipedia, including it in the knowledge base (RAG) makes the agent pay more attention to the added text.
1. كم مرة يتم طلاء برج إيفل من الدور الأول إلى القمة؟ 1. How often is the Eiffel Tower painted from the first floor to the top?
1. كل 5-7 سنوات. 1. Every 5-7 years.
Once the questions were validated and corrected, they were applied to an agent whose prompt was in the respective language. The human evaluator then applied the question bank, recording the evaluation criteria for each metric. For instance, if the answer to the question had no grammatical errors, the score was 1. If there were some errors, the score was 0.75, and if there were number or gender errors, the score was 0.5 (since this is the most common error in translators that use English text as a knowledge base). After noting all the metrics, the results were saved for a descriptive analysis.
The experiments were conducted in both languages and three models were evaluated. Since these models meet all the client requirements, also are available from CodeGPT as provider:
- Llama3 70b (Meta — AWS)
- Command R Plus (C-R from Cohere)
For a quality reference, we will use GPT4 (OpenAI).
Results in English
This test is only for reference, I needed a baseline to understand how the agent responded in English (knowing the background I mentioned regarding the training). Despite its undeniable quality in the market, GPT4 was not the one that obtained the best metrics in contrast with Command R Plus, which scored 99 out of 100 points.
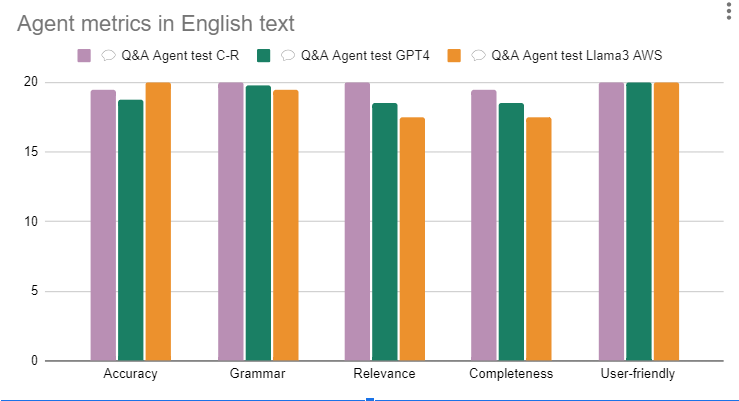

Final results: The measures are out of 20, with 1 point for each question.
Undoubtedly, we also measured the response time, where Llama3 70b had an average of 1.23 seconds, surpassing GPT4 with 5.23 and C-R Plus with 3.25 in speed.

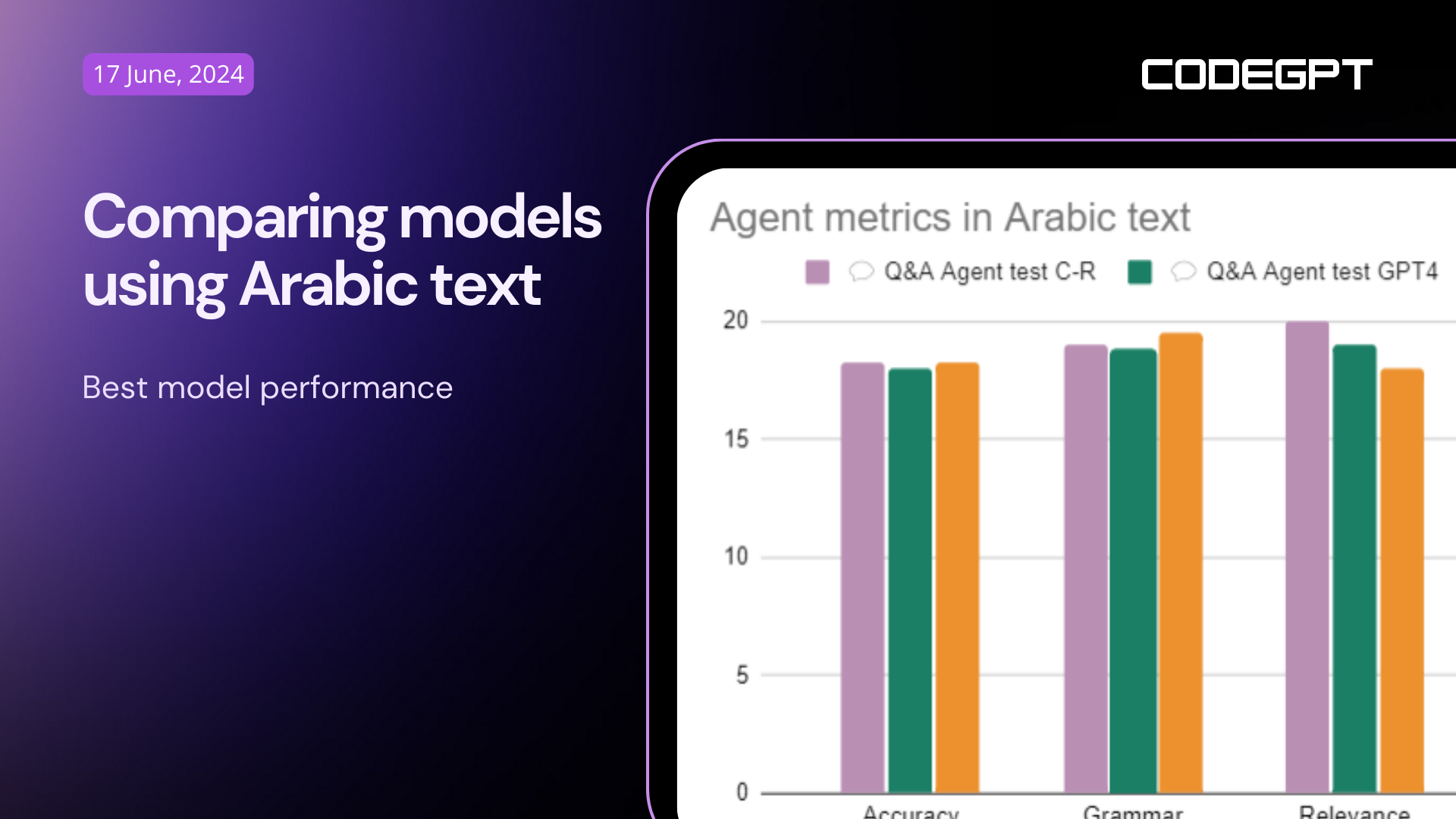
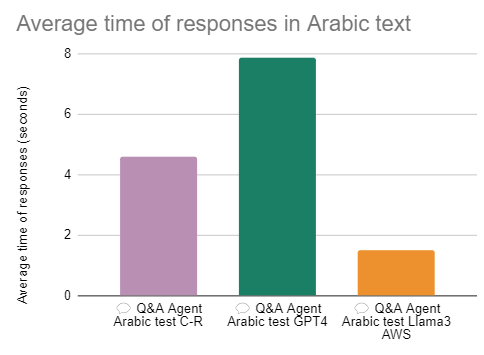
Results in Arabic
In Arabic, the scores are lower than in English, no model surpasses 97% of responses that meet the evaluation criteria. However, 97% is still more than acceptable, but in these tests, apart from showing the same results from the procedure in English, I am going to focus on the errors that were noticeable in the models in at least 2 questions.
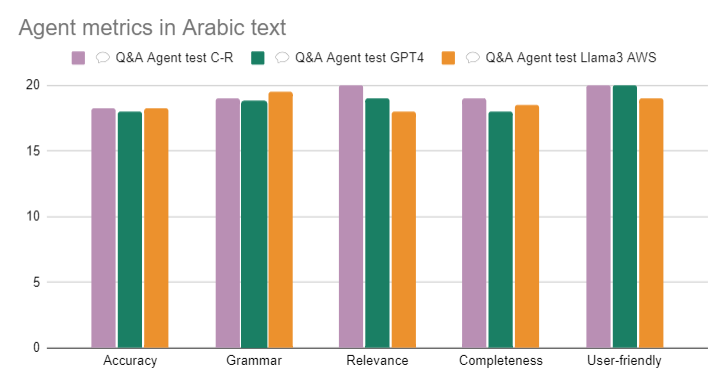

Final results: The measures are out of 20, with 1 point for each question.
Similarly to the experiment in English, the model with the shortest response times was Command R Plus.
Order and numbers
Grammatically, the differences between English and Arabic were more than obvious. This was mainly expected due to the configuration of the languages, and with English being the predominant language in the knowledge base of the models, the grammatical errors were of two types: The order of words (in Arabic from right to left), numbers (quantities).
- Order: For instance, in question 18 "Who manages the gourmet restaurant Le Jules Verne in the Eiffel Tower?" the answer is: The restaurant is managed by Alain Ducasse and his group. In the agent's response, the name Alain Ducasse was translated into Arabic (ألين دوكاس), but the clarification of the name in the original language was incorrectly placed within the sentence and not to the left of the name for reference.
يدير فريق ألين دوكاس (Alain Ducasse) مطعم لو جول فيرن في برج إيفل.

Question 19 has a similar clarification in parentheses about the number. And this was the response from GPT4:
Question: What was the height of the Eiffel Tower at the time of its completion? Answer: The height was 300 meters (984 feet) at the time of its completion.

Numbers
In Question 4, the answer implies numerical quantities, specifically pressure, in square centimeters. In English, the answers did take into account the square centimeters, but in Arabic, the number 2 was not written in the correct format.
Question: What is the pressure applied on the cement foundations of the Eiffel Tower? Answer: Between 4.5 to 5.3 kg/cm² depending on the pillars.
Command R Plus: الضغط المطبق على الأسس الاسمنتية لبرج إيفل لا يتجاوز 4.5 إلى 5.3 كلغ/سم2.
GPT4: الضغط المطبق على الأسس الاسمنتية على الأرض، المتكونة من الرمال والحصى، لا يتعدى 4.5 إلى 5.3 كلغ/سم2 تبعاً للأعمدة.
The models with the highest number of grammatical errors in arabic was GPT4 and Command R Plus, but despite them, a native speaker could understand them more and they were more accurate than the answers from GPT4.
Conclusions
The model with the best performance is Command R Plus, compared to GPT4 it doesn't compromise the quality of the response and can do so in reasonable waiting times.
It's important to know that the training data of the models have a larger volume in languages like English. Therefore, it's crucial to test it with other languages, in this way making generative AI accessible to everyone.
In a future experiment, we will test different models, both locally and on remote servers, with other languages. Additionally, we will experiment with various "chunkerization" strategies to determine which is best for a particular language. Perhaps we'll even run a CodeGPT lab, just for fun.
.png?width=352&name=Copy%20of%20nombre%20agente%20versi%C3%B3n%20(4).png)

Leave a Comment