


-1.png)
We have previously discussed the significance of RAG for LLMs. Essentially, if you need an LLM to answer specific knowledge-based questions, we integrate RAG into the query process with specific information. However, this idea still presents challenges, as the chunks used to generate responses may contain irrelevant information, leading to hallucinations. A few weeks ago, at CodeGPT, we decided to conduct experiments to verify if RAG can enhance according to 3 criteria regarding chunks:
- Evaluate chunking strategies
- Define the cosine similarity threshold
- Incorporate a Reranker model
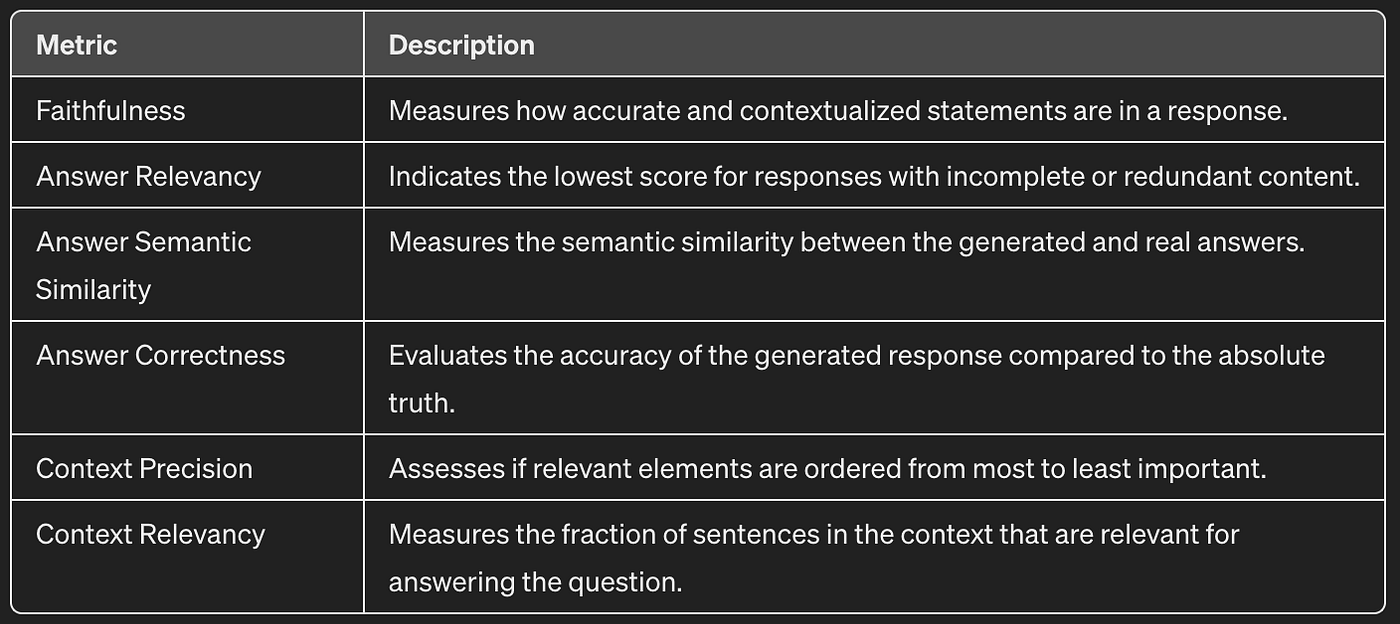
After some research, we came across Ragas, a framework that utilizes LLMs as evaluators based on questions, answers, and context. Ragas comprises various metrics ranging from 0 to 1. Specifically, we focused on the following metrics:
For our dataset, we utilized information from the Wikipedia page on Peru. An important consideration is that some Ragas metrics require knowledge of the real answer to a question (ground truth) as well as the response generated by the LLM. Therefore, we decided to generate sets of questions and answers based on different contexts using GPT-4-Turbo. The context was extracted from the Peru article, and we asked the LLM to generate two questions along with their respective answers using this simple prompt:
You are an agent generating questions and answers about a context. The user will paste the text and should formulate 2 questions and answers from this text. The number of questions will always be 2; they should be displayed as follows, Example:
Questions:
1. What was the expansion process of the Inca Empire, and who were its main rulers?
2. How was society organized in the Tahuantinsuyo before the arrival of the Spanish?
Answers:
1.The expansion process of the Inca Empire, known as Tahuantinsuyo, began in the 15th century and extended until the arrival of the Spanish in the 16th century. It was initiated under the leadership of Pachacútec, who transformed the Kingdom of Cusco into a vast empire.
Society in Tahuantinsuyo was highly organized and hierarchical. At the top was the Sapa Inca, considered a divine being. They were followed by the Inca nobility, composed of relatives and associates of the Sapa Inca, and the curacas, leaders of the conquered peoples.

It’s important to mention that the results were subsequently validated by ourselves.
This is the first article in a series of three, which will explain each experiment. We will start with the Chunking Strategies.
Chunking Strategies
After obtaining our dataset, we applied different chunkerization methods to obtain the necessary embeddings for similarity search. We tested three different ways of dividing the document:
- Langchain RecursiveTextSplitter: Generates chunks each time it encounters a splitter from a set of splitters. Chunk size was 512 tokens with a 50% overlap.
- Llama-Index SentenceSplitter: Takes a maximum token window and cuts at the nearest sentence end. Chunk size was 512 tokens with a 50% overlap.
- Semantic-Router RollingWindowSplitter: Divides the document into sentences and evaluates similarity between them, concatenating based on a specified window. This splitter can determine the optimal similarity threshold for concatenation or new chunk generation. In our case, we used a window of 1 with a maximum size of 500 tokens per split. We used the text-embedding-3-small model from OpenAI to calculate similarity.
After obtaining the chunks, we calculated their embeddings using the text-embedding-3-small model. We obtained a total of 468 chunks for the Langchain RecursiveTextSplitter, 89 for the Llama-Index SentenceSplitter, and 196 for the Semantic-Router RollingWindowSplitter. Below is the result of the document division:

As a first test, we opted to visualize the embeddings using UMAP and a specific keyword. Below are images of the 2-dimensional vector space for each splitter. The cross indicates the position of the keyword in the vector space, while the points enclosed in circles represent the 10 nearest chunks in terms of cosine similarity.
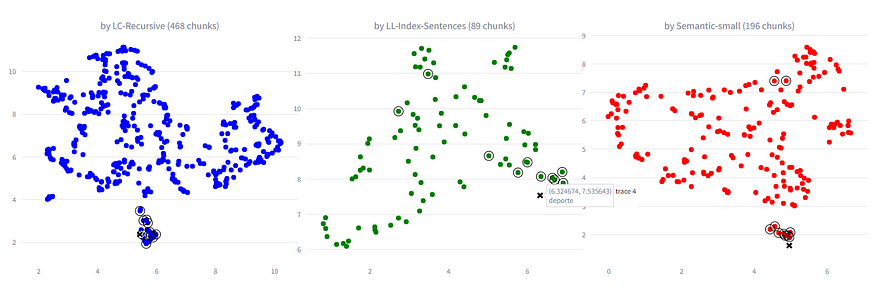
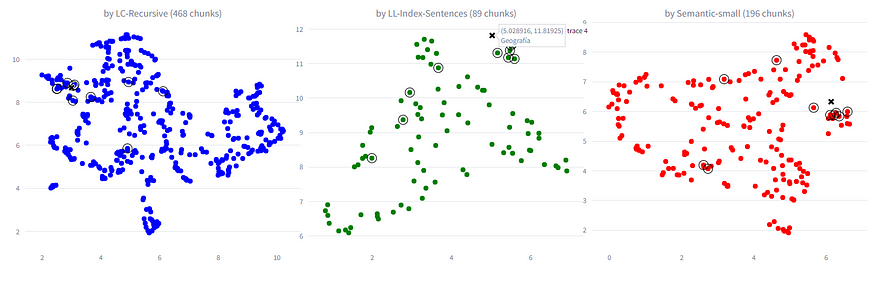
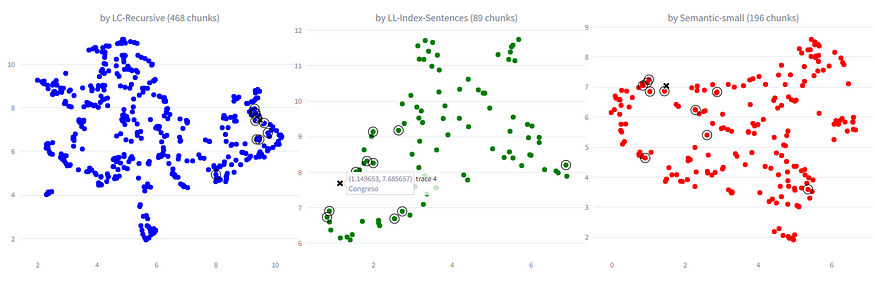
It can be observed that the Langchain RecursiveTextSplitter shows the least dispersed embeddings in UMAP, followed by the Semantic-Router RollingWindowSplitter, and finally the Llama-Index SentenceSplitter. These results initially suggest that chunks obtained with Langchain could be more specific and therefore more suitable for RAG. However, we also expected the semantic splitter to provide better chunks due to its more structured approach to cuts.
The next step in using Ragas is to answer questions using different strategies. For this, we used GPT-4-Turbo with the following system prompt:
Perú Agent
You are an assistant for question-answering tasks. Use the following pieces of retrieved context.
(Knowledge) to answer the question. If you don't know the answer, just say that you don't know. Read these Knowledge carefully, as you will be asked questions about them. Keep the answer concise. Always answer related to the Knowledge.
---
# KNOWLEDGE:
<Documents>
{knowledge}
</Documents>
Now, we used the complete question to obtain the nearest chunks, which were then used in the knowledge field of the system prompt. For practical purposes, we evaluated two top-k chunk cases: 1 and 5.
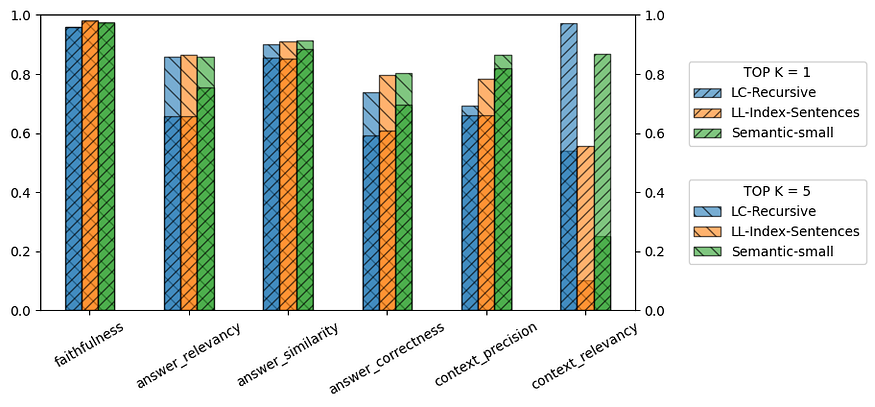
- Faithfulness: The metric shows a predictable outcome for an LLM like GPT-4-Turbo, as it can generate convincing responses regardless of the splitter used and the number of chunks provided as context.
- Answer Relevancy: A significant difference is observed when using 1 or 5 chunks as context. It is logical for the metric to improve with a higher number of chunks, as the LLM receives more contextual information. The improvement with semantic splitters suggests that variety in content in the context can positively influence this metric.
- Answer Semantic Similarity: This metric shows similar results across all splitters, with a slight improvement in the semantic splitter.
- Answer Correctness: A substantial difference is observed when using 1 or 5 chunks, indicating that with less context, the LLM has fewer reference points or facts to generate responses. It’s interesting that the semantic splitter does not experience such a pronounced drop, suggesting that the quality of content in the chunks is more critical than in other splitters.
- Context Precision: The semantic splitter demonstrates a clear advantage over others, indicating that the order of chunks provided as context is more accurate for answering the question. Remarkably, the Llama-Index splitter is more affected when reducing from 5 to 1 chunk, suggesting that the first chunk delivered is not always the most relevant.
- Context Relevancy: This metric is interesting but may be confusing at first glance. Using 5 chunks shows a significant impact across all splitters, which makes sense given the higher number of sentences that introduce more noise. The excellent performance of the Langchain RecursiveTextSplitter, achieving similar results to 1 chunk with the Llama-Index splitter, possibly stems from smaller chunk sizes containing less noise.
In conclusion, the results suggest that a semantic splitter is a good choice, even with only 1 chunk. The Peru document had a total of 45,000 tokens, resulting in minimal consumption of just US $0.0009. Additionally, unlike other splitters, this method does not randomly split sentences, especially in places separated by line breaks. As a second option, the Langchain RecursiveTextSplitter also demonstrates good results.
Regarding how the LLM responds, the results indicate that for LLMs like GPT-4-Turbo, noise in the RAG system context does not affect much as long as it contains the correct answer somewhere. However, token consumption plays a crucial role. The following figure shows a histogram of token usage per chunk according to each splitter:

If we calculate the average, we observe that the Langchain RecursiveTextSplitter consumes approximately 100 tokens per chunk, the Llama-Index splitter around 500 tokens, and the semantic splitter about 225 tokens. How does this translate into daily usage by a user? Let’s assume that in one context, 5 chunks are used, and a user makes about 10 queries per day for a month. With the current price of GPT-4-Turbo (US$10 / 1M tokens), this equates to a cost of approximately US$1.5, US$7.5, and US$3.375 respectively for each splitter. In other words, using the Llama-Index splitter would be 5 times more expensive than the Langchain RecursiveTextSplitter and more than 2 times more expensive than the semantic splitter. For an individual user, this may not seem costly, but what if we consider 100 or even 1000 daily users? That’s when token consumption becomes relevant.
However, another issue arises: not all documents have the same structure, so allowing a splitter to automatically chunk the document is not always ideal. Imagine a scenario with a document that includes a table; it’s very likely that the mentioned splitters will cut the table into several parts, completely losing its structure. In contrast, by setting a maximum token limit, as the Llama-Index splitter does, we could keep the entire table within the context.
At CodeGPT, we prefer to use the semantic splitter, although we have also found the Llama-Index splitter useful for other document types. Currently, we are developing a platform that will allow users to perform much more guided and functional chunkerization, with the goal of ensuring that only chunks with relevant information reach the LLM.
Chunks configuration in the CodeGPT playground:
In the next article, we will discuss the evaluation of Semantic Similarity in chunks. Don’t miss it! Stay tuned for part 2 and part 3.
Resources:
CodeGPT: https://codegpt.co/
Langchain: https://www.langchain.com/
LlamaIndex: https://www.llamaindex.ai/
RAGAS: https://docs.ragas.io/en/stable/
Semantic Router: https://github.com/aurelio-labs/semantic-router
-1.png?width=352&name=Maqueta%20(4)-1.png)
-1.png?width=352&name=Maqueta%20(6)-1.png)
-1.png?width=352&name=Maqueta%20(7)-1.png)
Leave a Comment