


-1.png)
Using Reranker
As we delve into this fascinating topic, it's time to critically assess the semantic similarity. This article aims to shed light on this complex yet vital aspect of the LLM technology.
In the context of LLMs, a Reranker will indicate how relevant the content of each chunk being passed as context is. It will deliver a relevance metric that ranges between 0 and 1, which is very useful for ordering the chunks and even for filtering them by defining a threshold.
In our case, we have used the rerank-multilingual-v2.0 model from Cohere. The graph below shows the relevance of each chunk according to the question for each splitter, similar to how we did with similarity. It is essential to mention that in this graph, the order of the positions is led by similarity.

We see a trend to leave the first chunk as the most relevant in most cases, which tells us that ordering by similarity is partially wrong (just a little bit). When comparing the three splitters visually, there are a few differences. However, if we were to order the chunks by relevance, we would see that for the Langchain splitter, 23.5% of the chunks maintained their position, for the Llama-Index 22.9% and the semantic one, 26.9%, which indicates that the semantic splitter is the one that is least affected with the use of a Reranker when wanting to order the chunks by relevance.
Let's see earlier with the index. 1: for the Langchain splitter, indeed, the second chunk is the one with the highest relevance, with a value of 0.99. The same happens for the semantic splitter with the first chunk, whose relevance is 0.98. However, for the Llama-Index splitter, the relevance is not higher in the second (which contains the answer), but in the eighth, with a relevance of 0.99:
- Question: What is the function of the intergovernmental committee according to Article 18 of the Convention on Intangible Cultural Heritage
- Relevant context: Article 18 of the convention stipulates that the intergovernmental committee selects programs, projects, and activities for safeguarding intangible cultural heritage that best reflects the convention's objectives.
- Chunk 8 Llama-Index: It is about blocks carved by which water runs on a gentle slope, which includes tunnels and zigzag elbows to slow down the current. The stone blocks at the route's begiroute'save various carved and polished planes. One of these blocks, shaped like a truncated cone, is traditionally known as the "sacrifice one." Within the "Moche cultures to the north and Nazca to the south, the first States with permanent militias were developed, linked to the most valued ceramic art pieces of Ancient Peru.44 In the extreme south, meanwhile, Tiahuanaco emerged as the dominant culture of the Altiplano.45 Later, the Wari culture developed the classic model of the Andean State with the emergence of imperial court cities, a model that expanded to the north towards the 18th century. From the 9th century, after the abandonment of Huari, new centralizing States of regional scope were erected along the Andes mountain range, such as Lambayeque, Chimú, and Chincha, a period known as the Late Intermediate or Regional States.46 Among these lordships, the Incas stand out, who by the 15th century had annexed all the Andean peoples between the Maule and Ancasmayo rivers, with an extension of two million km²,47 today located in the territories of southern Colombia, western Ecuador, Peru, western and central south Bolivia, northern Chile.
Undoubtedly, this is a wrong result from the Reranker. We cannot expect it to be perfect, but with more advances, the accuracy of these models will improve. If we had ordered by relevance, the correct chunk (the second) would be within the top 5 most relevant chunks, although with a relevance of 0.005.
How does relevance compare with similarity? Check the graph below:
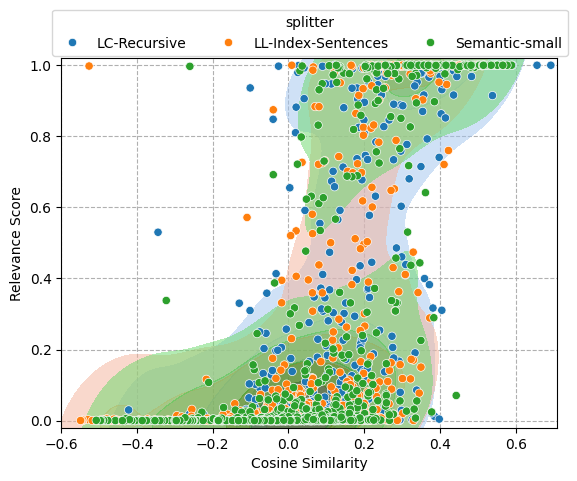
A sort of sigmoid function is observed, where shallow values in similarity have no relevance, and high values are very relevant. However, the graph has two things that would bother anyone:
- The dispersion at the inflection point is too high, with similarity values ranging from 0 to 0.4.
- There are several outliers at both ends: some with very negative similarity but very relevant, and others with high similarity (~0.4 for our example) but no relevance at all.
On point 1, we already discussed on Part 2, that similarity can be unreliable. On point 2, let's observe the behavior of similarity and relevance according to the position (ordered by similarity) of each chunk:

We see that the shape of the similarity distribution among the three splitters remains the same in the different positions, the only change being a gradual decrease in similarity as the position advances. Regarding relevance, the distribution is much more dispersed and shows little structure concerning position. For the chunk in the first position, the Llama-Index splitter shows a more excellent dispersion than the rest, indicating that when ordering by similarity, this is the worst of all. The second position shows a high dispersion in all three cases, and as it advances, this decreases, although maintaining a high number of outliers.
We could order the 10 chunks by relevance. The problem is that for such sophisticated LLMs as GPT-4-Turbo, no matter how much we modify the order of how the context is passed, the answer will remain the same (only if we are not using a massive amount of tokens). We are then left to study what would happen if we define a threshold to filter chunks. The following figure demonstrates the impact of the number of questions lacking context, similar to the approach taken with similarity:
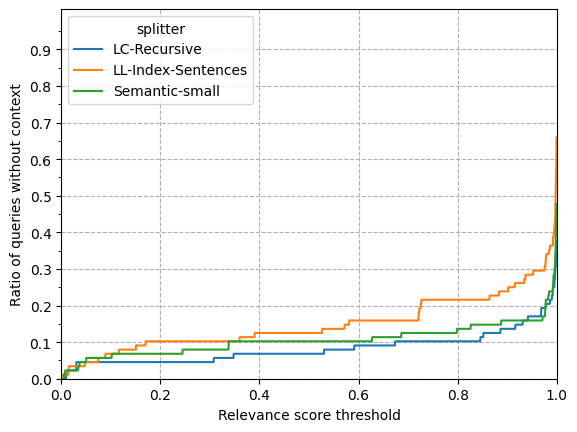
Regarding the similarity, the graph doesn't show an exponential increase, and even with a significant value of 0.5, only 10% of the questions would need more context. We also note that the Langchain splitter and the semantic one are the least affected when setting a threshold. But here is something we have not seen yet, and that is the distribution that relevance has:
-1.png?width=352&name=Maqueta%20(5)-1.png)
-1.png?width=352&name=Maqueta%20(7)-1.png)
-1.png?width=352&name=Maqueta%20(3)-1.png)
Leave a Comment