


-1.png)
The world of artificial intelligence, and specifically language models, has witnessed significant advancements in recent years. Current language models are capable of generating remarkably coherent and relevant text. But what lies behind this progress? The answer is the concept of "vector".
A vector is a mathematical representation that allows encoding of information, such as text, documents, images, audio, etc., in a multidimensional space. This representation makes it easier for computers to understand the relationships between concepts.
For example, a language model like text-embedding-ada-002 or all-minilm-l6-v2 can capture the semantic relationships and characteristics of data and represent them in the form of numerical vectors, known as embeddings.
What are embeddings and what are they used for?
Embeddings are vectors that capture the semantic meaning of information. This means we can compare different embeddings and see how similar or different they are. For example, we could compare the information from a manual with a user's question by transforming both texts into embeddings and then comparing them.

Embeddings have multiple applications, including:
- Search: results are ranked by relevance to a query.
- Clustering: text strings are grouped based on similarity.
- Recommendations: items with related text strings are recommended.
- Anomaly detection: outliers with little relation are identified.
- Diversity measurement: similarity distributions are analyzed.
- Classification: text strings are classified based on their most similar label.
In summary, each point in a vector space represents a vectorized concept.
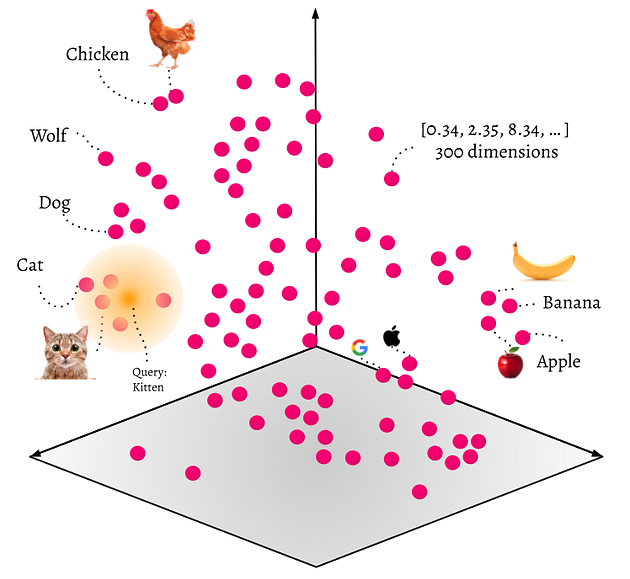
Vector Search
Traditional search engines perform searches based on keywords. However, these engines have limitations, especially when semantics play a crucial role. This is because they do not take into account the actual meaning of the query and the related documents or data.
This is where vector-based search, also known as semantic search, comes into play. Unlike traditional search, vector-based search retrieves data by its meaning rather than by coincidence.
Various techniques are used to determine the similarity between vectors, with the most popular one being cosine similarity, which measures the angle between two vectors to determine their directional similarity.
Each search function has its advantages and disadvantages, and the choice of the appropriate search function depends on the nature of the vectors and the specific requirements of the application.
Integrating the results of semantic searches into the model
The integration of results from semantic searches into a language model involves the use of a technique known as "Retrieval Augmented Generation" (RAG). This technique combines semantic search and text generation to produce more accurate and contextualized responses.
First, a semantic search is performed, using a vector database (VectorDB) or a similar method, based on the question or context provided to the model. This semantic search returns a list of documents or text snippets considered relevant to the question.
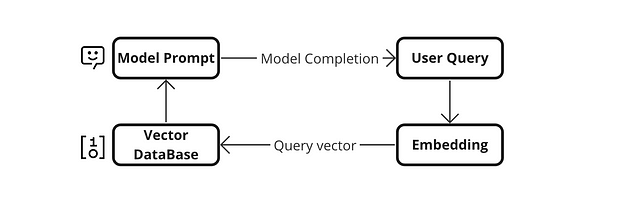
The retrieved documents are combined with the original question and presented as input to the language model, such as GPT-3.5-turbo, for example. This model takes information from both the question and the documents to generate a coherent and contextualized response.
The language model generates the final answer based on the information from the question and the document retrieval. By understanding the context and word relationships in the retrieved documents, the model can generate more accurate and appropriate answers. Integrating semantic search with the language model allows leveraging the knowledge contained in the relevant documents, significantly improving the quality of the model-generated responses.
This approach is particularly useful when you want the model to have access to specific and up-to-date information to answer questions in a more informed and contextual manner.
Final words
Optimizing language models using vector data provides a powerful approach to improving the quality and relevance of generated responses. By providing additional information to the context, models can understand and relate text more deeply, delivering more accurate results beyond their training.
This integration of information retrieval with text generation opens up a world of possibilities for customizing and refining the interaction experience with artificial intelligence.
By continuing to explore and experiment with these strategies, there is no doubt we will continue to witness significant advances in the development of automated response systems that increasingly meet the needs and expectations of users. The language model revolution is underway, and vector data is leading the way toward smarter and more effective communication.
-1.png?width=352&name=Maqueta%20(4)-1.png)
-1.png?width=352&name=Maqueta%20(5)-1.png)
-1.png?width=352&name=Maqueta%20(6)-1.png)
Leave a Comment